I re-ran the AI Stroop paper on the 2026 frontier. The deficit is real, but the goalposts moved.
A viral paper says transformers fail a 90-year-old attention test as the list gets longer. I reproduced it on the 2026 models. The deficit is real. The cliff just moved out.
One honest note first. I directed this. I didn't do most of it. My AI cofounder built the harness, ran the thousands of model calls, did the analysis and the charts, and wrote the first draft. I set the questions, pushed hard on the results, and edited. (It also ran the analysis on a couple of the models it's related to. The scoring is mechanical and the data is reproducible, so that doesn't color the numbers.) A post about what AI can't do shouldn't be coy about what AI just did.
A friend sent me a paper today. It's been making the rounds: "Deficient Executive Control in Transformer Attention" (Patel, Wang & Fan, PNAS Nexus, June 2026). The headline is alarming. So I did the thing I always wish more people did with an alarming headline. I tried to reproduce it.
I had Perplexity run a deep-research pass to get oriented. Then I read the open-access paper. Then I built the task and ran it on current models. Here is what I found, including the part where I almost fooled myself.
What the paper found
The Stroop task is simple. You see the word "RED," printed in blue ink. Name the ink color, not the word. Easy for you. Harder than it looks for a model.
The authors tested GPT-4o and Claude 3.5 Sonnet. On short lists, both did fine. As the list grew, accuracy fell off a cliff. GPT-4o went from 91% right at 5 words to 15% at 40. The control conditions held up the whole time. So it isn't a vision problem, and it isn't a memory limit. It is a failure to hold one rule ("name the color") while a stronger habit pulls the other way.
They call it deficient executive control. The argument is structural. Transformer attention is good at orienting, at choosing what to look at. It has no real machinery for noticing conflict.
The viral version is blunter. The demo is always short. The real work is always long. The long one is where AI breaks.
Two things made me want to check. The paper's main data is on 2024 models. They sampled a few newer ones, but only n=5, and they stopped at 40 words. Does it still hold on the actual 2026 frontier? And where exactly does each model break if you keep going past 40?
First: the replication holds, closely, at short lengths
I rebuilt the real task. Images of color-words in clashing ink. Name the inks, top to bottom. Fresh session every trial, the same seeded images for every model, low reasoning effort throughout (more on that below). Then I ran GPT-4o against the paper's own numbers.
| list length | paper (GPT-4o) | my replication |
|---|---|---|
| 5 | 91% | 87% |
| 10 | 57% | 58% |
| 20 | 22% | 38% |
| 40 | 15% | 30% |
Look at 5 and 10 words. I land almost exactly on their curve. 57 versus 58 is about as close as a replication gets. The collapse at 20 and 40 is the same shape. My numbers run a little high at the long end, from scoring tolerance and rendering. But it is their effect, reproduced.
Then I ran the 2026 frontier on the same task
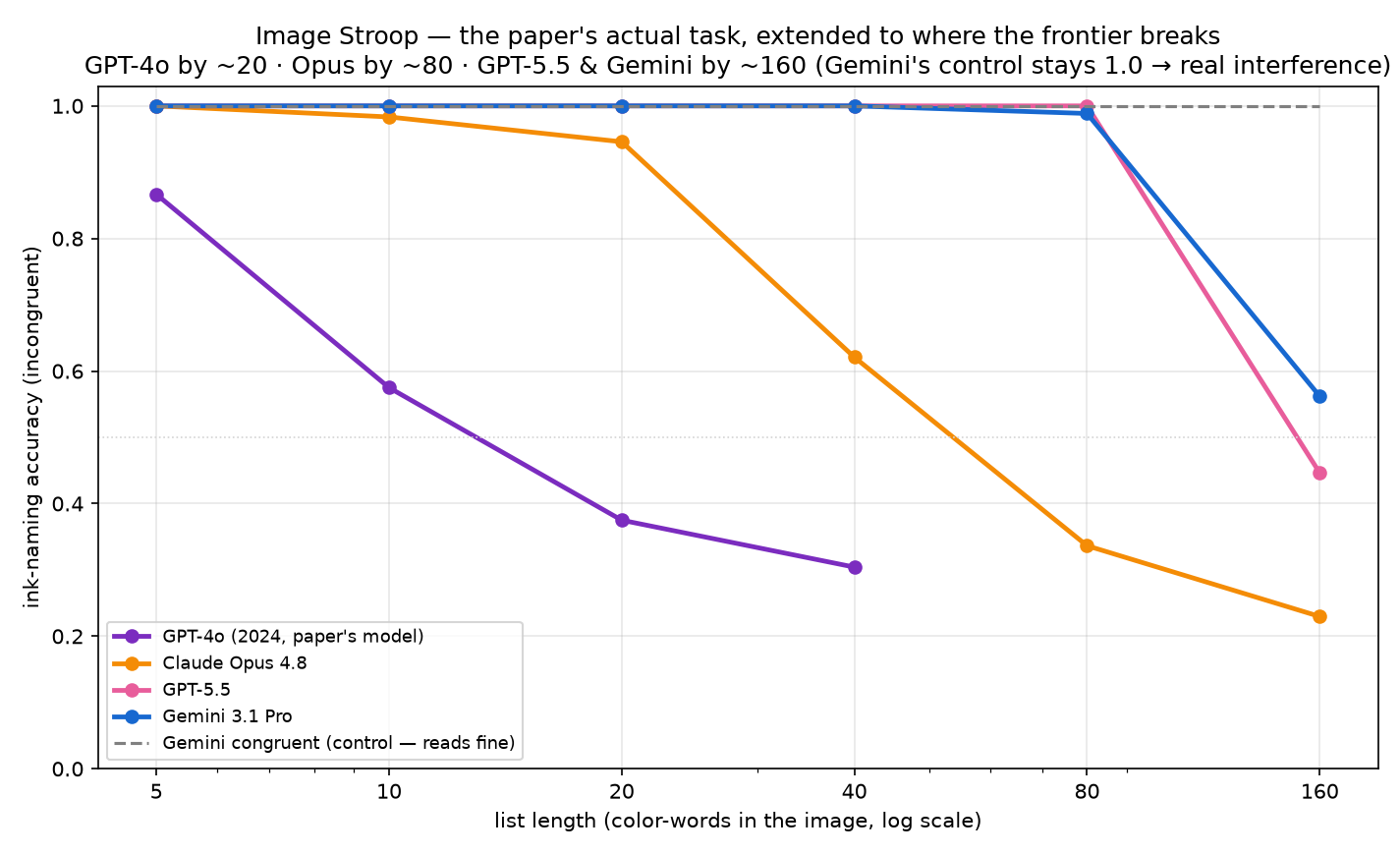
The current models are far better. They are not immune. That is the whole point. On the paper's actual visual task:
- GPT-4o breaks by about 20 words. The paper's result.
- Claude Opus 4.8 holds to 20, slips at 40 (0.62), and breaks hard by 80 (0.34).
- GPT-5.5 and Gemini 3.1 Pro sail through 80 untouched, then fall at 160. Here I have to be careful. By 160 the image is tiny. GPT-5.5's congruent control has dropped to 0.54, so it can no longer reliably read the words. Its conflict score there is part legibility, not pure interference. Gemini is the clean case. At 160 its congruent control is still a perfect 1.00. It reads everything. And it still halves on conflict, to 0.56. That is the one frontier break I fully trust on the image task.
So the deficit did not vanish. The cliff moved, from about 20 words out to roughly 80 to 160. A few-fold gain. (Eyeballed break-points, octave-spaced lengths, n=12. Not precise thresholds.) The wall is much further down the hall now. It is still there.
The skeptic's check (I had the same reaction)
A flat 1.00 looked too clean to me. So I read the raw outputs. The models return the full list every time. They name the ink, which in a conflict trial never matches the word. If they were reading the words instead, they would score near zero. They are suppressing the word and naming the ink, item by item. The score is real. (Humans sit around 95 to 97% on Stroop, for what it's worth. A model with enough control just does it. Until the list gets long enough.)
Gemini at 160 is the cleanest data point in the whole thing. It reads all 160 words perfectly in the matching condition. Legibility is fine. Yet its conflict accuracy halves. Same image, same word count. The only thing that changed is whether the word fights the ink. (A purist would say a matching list can be solved by just reading the word, so this isn't an airtight test of color perception. Fair. But nothing else explains a halving on the conflict items alone.)
How far the text version stretches
The image goes illegible past about 160 words. It turns into a skyscraper of tiny text. So I also ran a text version of the same clash: word: RED · ink: blue, report the ink. That scales to hundreds of items, with no pixel ceiling.
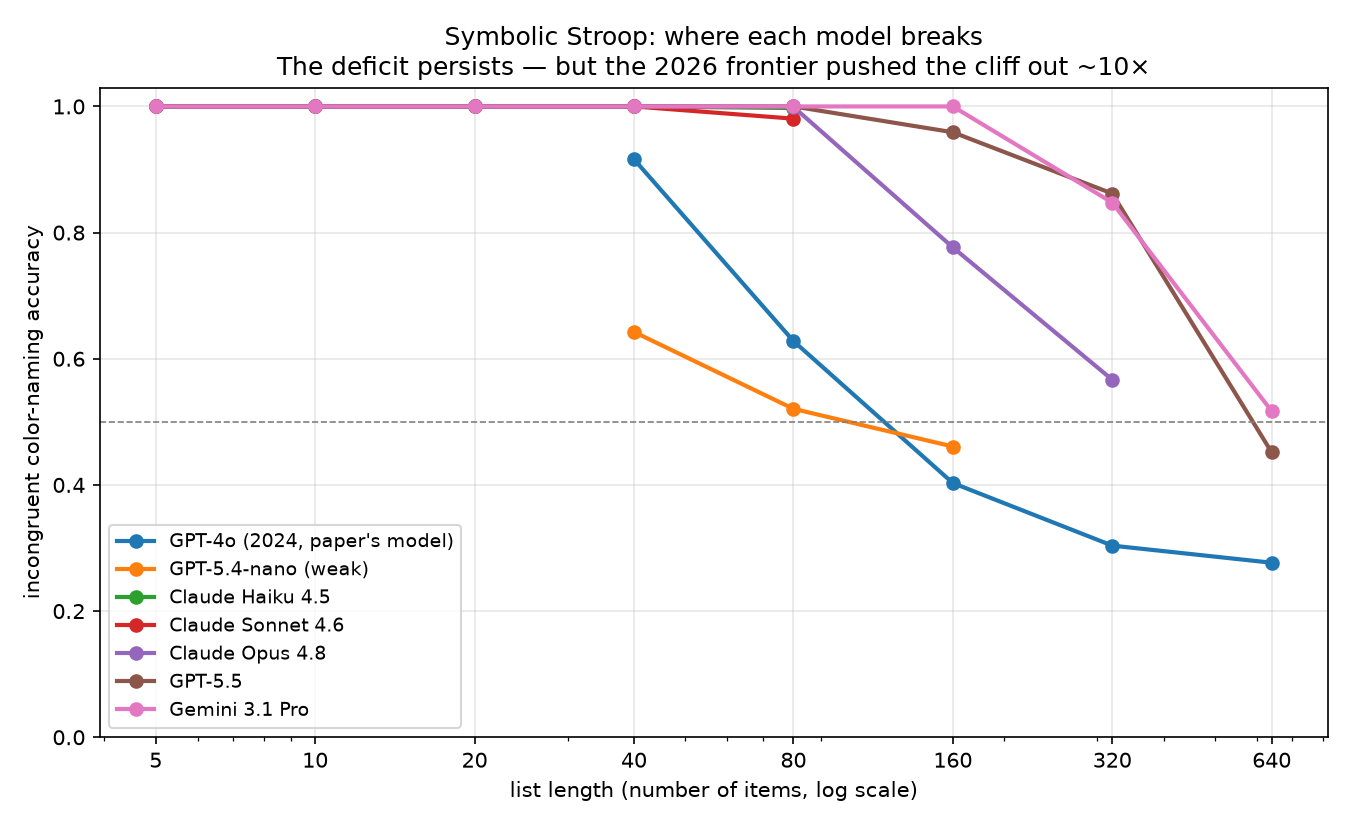
The text version is easier. Every model lasts longer than it does on the image. But the cliffs are still there, just further out. GPT-4o slides early here too, down to 0.28 by 640. Opus breaks by about 320. GPT-5.5 holds to 320 (0.86), then breaks by 640 (0.45). Gemini is still at 0.52 at 640, the furthest I tested.
One honest caveat. I won't call that gap "purely perceptual." There is a catch in my own setup. The text format writes the answer into the prompt, as a labeled field (ink: blue). That turns a read-versus-name conflict into something more like picking the right field past a distractor. Related, and it still breaks with length. But not the same mechanism. So I treat the text numbers as a way to push the length axis past the image's legibility limit. Not as a second clean Stroop.
The control I leaned on the whole time was the congruent condition, word and ink matching. It stays near-perfect even on the longest lists, for every model. Same length, same counting load. No conflict to resolve. Things fall apart only when the word fights the ink. That is the signature of interference, not lost count.
What I'm not claiming
A few things this is not.
- It is not a study. n=12 to 20 per cell, one run, eyeballed break-points. I sampled lengths at 5, 10, 20, 40, 80, 160, 320, 640. Not every value.
- I ran everything at low reasoning effort, on purpose. The paper notes that GPT-5 in "Thinking" mode beats the task by writing and running code. That routes around the deficit with a tool. It does not show executive control. Low effort keeps the measurement about the model. Turn the effort up and the numbers improve, but you are measuring something else.
- At 160 the image is near the legibility ceiling for several models. GPT-4o can't read it at all. GPT-5.5 and Opus are partly degraded on the control too. That is why I lean on the congruent control, and why Gemini, still clean at 160, is the seat I trust there.
- The paper already showed the deficit survives into newer models. I am extending their small newer-model pass, with a bigger sample, the real 2026 frontier, and the break-points they did not chase past 40. I am not discovering it.
So what's it actually good for
This is less scary than "AI is broken," and more useful. Skip "is the model deficient." The answer is yes, eventually, for all of them. The question that helps you ship is different. Is your real task longer than this model's break-point? And is it the easy kind of long, or the hard kind?
A model that's perfect at 40 items and useless at 160 is a great tool. If your job is 40 items. It is a quiet liability if your job is 160 and nobody checked. And "long" is not one number. A high-interference visual task breaks a model several times sooner than a clean text one of the same length.
Here is the part that survives all the way to the frontier. The model does not know it is failing. No wobble. No hedge. No drop in confidence. It hands you the wrong answer at 160 in the exact tone it used for the right one at 20.
That is the whole problem in one line. When I built my own forecasting tool, the thing I wanted most was not a smarter model. I needed AI that was terrified of being wrong. This paper is why. The safeguard cannot be the model's confidence. It has to live outside the model. Keep each chunk of work below the break-point. Check the output against ground truth. Do not trust the tone.
The next model will push the cliff out again. I'd bet it won't remove the cliff.
Verify, then trust.
Thanks to Patel, Wang and Fan for a genuinely good paper. And to the friend who sent it my way. It was a fun thing to chase for an evening.
Method and sources
A note on rigor, because this is a replication. The conditions I ran: congruent, incongruent, word-reading. The lengths: 5 to 160 for images, out to 320 and 640 for text. The sample: n=12 per cell for images, n=20 for text. I did not run the full design. I left out the mixed, neutral, and nonword conditions, and the congruency-sequence analysis. So this is a partial replication of the core length-by-conflict result, not the whole study. One run, no statistical testing, approximate break-points. Same seeded stimuli, fresh session per trial, low reasoning effort throughout. Numbers and harness are reproducible on request.
On the paper's own numbers: I got oriented with a Perplexity deep-research pass, then confirmed the figures I quote (GPT-4o's 91% to 15%, and the near-perfect controls) directly against the open-access paper. My independent replication lands on the same curve.
Source:
- Patel, S. C., Wang, H., & Fan, J. (2026). "Deficient executive control in transformer attention." PNAS Nexus, 5(6), pgag149. paper · preprint
- ScienceDaily summary: "A classic brain test exposed AI's biggest weakness"
- Author's write-up: Suketu Patel, "Scaling transformer attention won't lead to AGI"