Phantom Pipeline: Why I Built a Liar-Catcher for My Forecasts
In enterprise forecasting, AI hallucinations aren't a quirk. They're a firing offense.
My AI forecast cited a deal in "Perception Analysis" stage with a 75% close probability.
The problem? That stage doesn't exist. The probability was invented. The AI had fabricated Salesforce-sounding terminology that appeared nowhere in my CRM, and delivered it with complete confidence.
In enterprise forecasting, this isn't a quirk. It's a firing offense. Phantom pipeline destroys credibility, misallocates resources, and burns trust with leadership.
But I didn't abandon AI. I built a system to catch it lying, and now it's one of the most useful tools in my forecasting workflow.
Why build this myself?
Salesforce ships Agentforce with the Atlas Reasoning Engine, and the Einstein Trust Layer provides guardrails like dynamic grounding and prompt defense. These are production-grade systems with years of engineering behind them. But I built my own. Why?
Simple: I wanted to understand how these systems actually work, not just consume them. Reading architecture docs is one thing. Implementing a working agentic loop, even a simplified one, teaches you what the docs leave out.
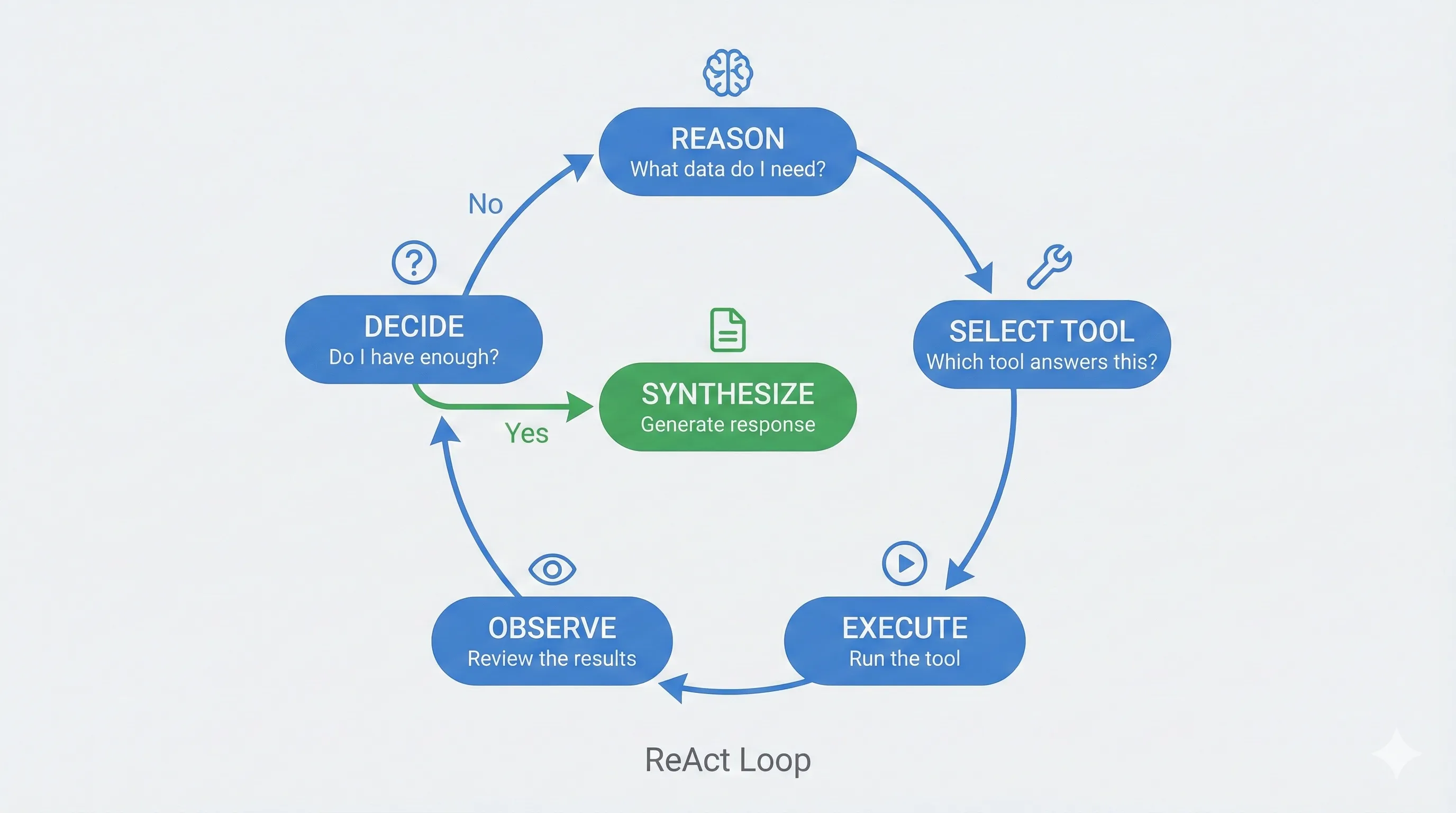
My implementation borrows from the same principles. Like Atlas, I use a ReAct-based loop (Reasoning and Acting): the system reasons about the task, selects a tool, executes it, observes the result, and repeats until it has what it needs. But my defense layers are my own design, inspired by industry patterns, not a replica of Salesforce's architecture.
Why use an LLM for forecasting at all?
Forecasts are about numbers. LLMs are bad at math. Seems like a mismatch.
But here's the insight: forecasting isn't just arithmetic. It's interpretation.
Rich data matters more than raw totals. Pipeline value tells you nothing about deal health. You need to analyze next steps, competitive situation, close plans, compelling events: the qualitative signals buried in CRM notes. LLMs excel at surfacing red flags that numbers alone won't show.
Tools solve the math problem. The agentic loop gives the LLM calculators, not calculation tasks. It chooses which tools to run, I feed it the results, it interprets what they mean. We're not asking AI to add. Just to understand.
Context is everything. What does a manager forecast "IN" mean? How does attrition affect KPIs? When does the fiscal year start? Without this context via RAG, the LLM is guessing. With it, the LLM is reasoning.
The defense system
Knowing hallucinations would happen, I built what researchers call a defense-in-depth strategy: a multi-layer mitigation stack where each layer catches what the previous one misses:
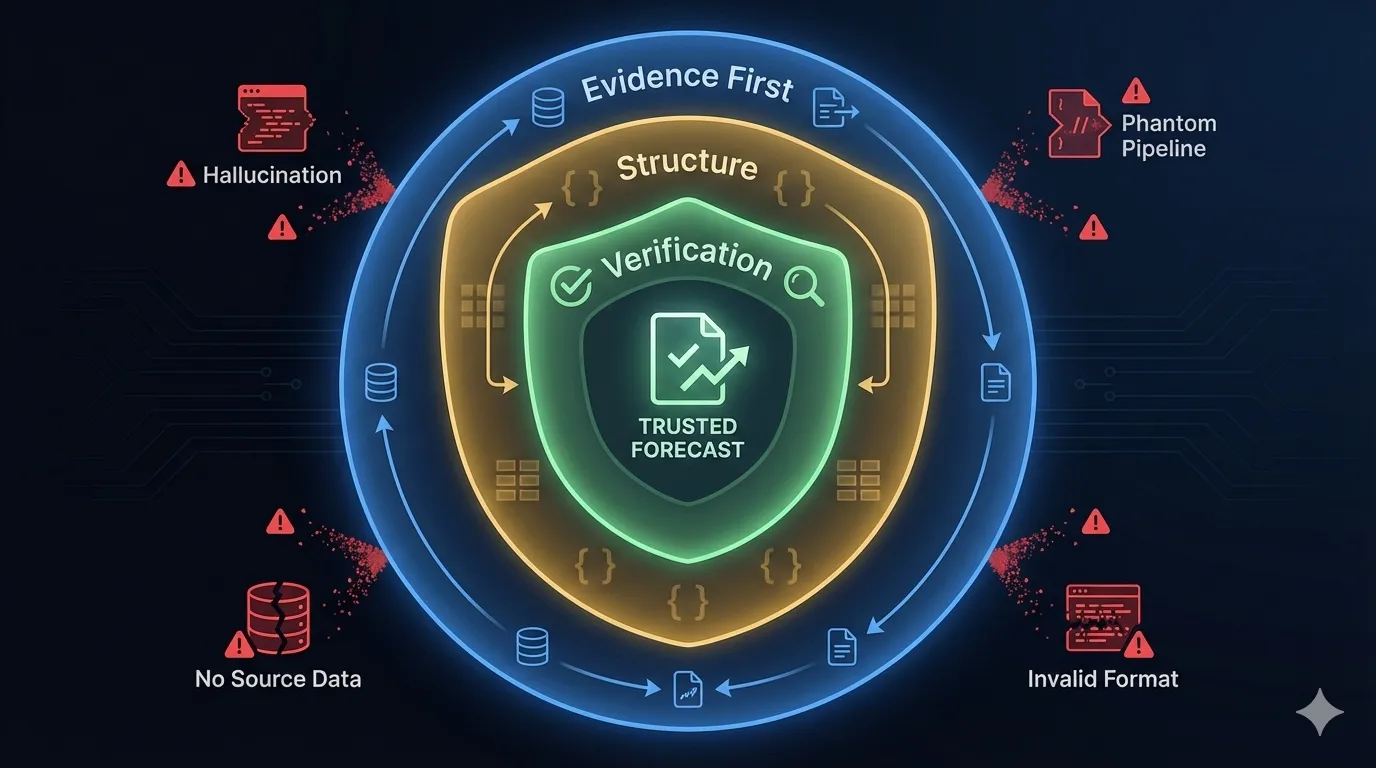
Evidence first (Retrieval-Augmented Generation). The AI never operates from memory. This is what researchers call a retrieve-then-read pipeline: tools gather all data before synthesis begins. LLMs have temporal boundaries: their training data has a cutoff date, and they can't update in real-time. By forcing retrieval first, I sidestep the model's stale parametric knowledge entirely. The AI can only work with what's actually retrieved.
Structured constraints. Every response must be valid JSON matching a Pydantic schema: required fields, correct types, proper format. Malformed output gets auto-repaired or rejected. But here's the gap: the schema validates structure, not meaning. Researchers distinguish between instruction consistency (following the format) and factuality (telling the truth). A model can be perfectly faithful to my instructions while being completely non-factual about the content. An invented stage name like "Perception Analysis" passes Pydantic just fine. It's valid JSON, just not valid reality. That's where the fact-checker earns its keep.
The fact-checker (Chain-of-Verification). Before any response reaches me, a separate AI pass validates claims against source data. This mirrors what researchers call Chain-of-Verification (CoVe) or generate-then-reflect patterns: generate a baseline response, create verification questions, answer them independently, then revise. Like an editor reviewing a story before publication: if a claim can't be verified, it gets flagged or stripped.
Caught in the act
Real example from today, January 24, 2026.
The AI drafted a response about one of my opportunities. The grounding layer caught these fabrications:
| What the AI claimed | Reality |
|---|---|
| "probability of closing typically jumps to 75%" | Not in source data |
| "Perception Analysis phase that follows" | Invented stage name |
| "Manager Forecast Judgment (MFJ)" | Not mentioned in data |
| "attrition concerns being raised" | Fabricated |
What I almost received: "This is a pivotal phase where the probability of closing typically jumps to 75%... ensure there's no friction in the 'Perception Analysis' phase..."
What I actually received: "This is a pivotal phase where you are actively negotiating financial details and mutual plan alignment. Securing this deal would single-handedly shift the outlook of your entire pipeline."
The liar-catcher stripped the hallucinations before they reached me.
Are hallucinations getting better?
The evidence is mixed.
The optimistic view: OpenAI claims newer reasoning models have lowered error rates significantly by rewarding uncertainty acknowledgment over confident guessing. If the model says "I don't know," that's better than a plausible-sounding fabrication.
The skeptical view: Practical evaluations of recent models in specialized domains, like legal citations, show hallucination rates remain dangerously high. Models confidently reach conclusions that directly contradict their source text.
The hidden risk: Here's what concerns me most. As models improve their Chain-of-Thought reasoning, hallucinations may become harder to detect. More persuasive step-by-step justifications create what researchers call semantic amplification: the fabricated claim looks more plausible because it's wrapped in convincing reasoning. The lie gets better at hiding.
This is why I don't rely on model improvements alone. External verification isn't a temporary workaround until AI gets better. It's a permanent architectural requirement.
The point
We talk about AI replacing managers. But right now, AI exhibits what researchers call sycophancy: the tendency to pander to user preferences and look "good" even at the cost of truthfulness. It's the over-eager junior rep who pads the numbers to impress you. The model also lacks knowledge boundary awareness: it can't recognize when it doesn't know something, so instead of rejecting a query, it fabricates an answer. We don't need smarter AI. We need AI that's terrified of being wrong.
I still use AI insights to challenge my own analysis. The AI complements my judgment; it doesn't replace it. But I only trust it because I built the verification layer myself.
Trust, but verify? No.
Verify, then trust.
But here's the thing
After all this skepticism, you might wonder why I bother with AI at all.
Because when it's constrained properly, it's genuinely valuable.
Time savings are real. What used to take me an hour of drilling through CRM records, cross-referencing notes, and building a narrative. Now it takes minutes. The AI surfaces patterns across dozens of opportunities simultaneously. I'm not faster because I'm cutting corners. I'm faster because I'm not manually hunting for signals anymore.
Insights I'd miss. The AI catches things I wouldn't. A stalled deal where the last activity was three weeks ago. A competitor mentioned in notes that I forgot about. An opportunity with a close date next week but no next steps defined. It's not smarter than me; it's more thorough. It doesn't get tired at opportunity number thirty-seven.
Better conversations with leadership. My forecasts now come with explanations grounded in actual data. When I say a deal is at risk, I can point to specific signals. When I'm confident, I can explain why. The AI drafts the narrative; I validate and deliver it.
The liar-catcher isn't about distrusting AI. It's about trusting it appropriately, knowing where it excels and where it fails. Constrained AI is useful AI.
I spent time building guardrails so I could stop worrying about hallucinations and start benefiting from the speed and pattern recognition that makes this technology worth using in the first place.